Cheap, always-on LoRA support
Published 2025-02-06
Thank you to everyone for supporting us since we launched billing last month! To help run custom finetunes cheaply, without needing to wait for model boots, we're launching cheap, per-token pricing for LoRAs for many base models: Llama 3.1 70B Instruct, Qwen 2.5 72B Instruct, and more. LoRA finetunes targeting these base models will stay always-on once uploaded, so you don't need to wait for model boots! We've also added a bundle of other new features:
- LoRA support
- Higher rate limits
- New sampler parameters in the UI
- DeepSeek V3 and R1
- Bugfixes, performance improvements, and UI tweaks
- Future plans
LoRA support
LoRAs — short for "Low Rank Adaptations" — are (relatively) small, efficient finetunes that modify some base model, like Llama 3.1 70B Instruct or Qwen 2.5 72B Instruct. Unlike a full-parameter finetune, we can quickly hot-swap LoRAs in and out of GPU VRAM for various base models, meaning that the LoRA finetunes stay always-on once they've been uploaded for the first time, and we can offer cheap, per-token pricing for them. LoRAs are still very effective at modifying base model behavior, so they're a great way to run custom models without having to pay the full price for full-parameter finetunes.
We've added a new section to our pricing page to cover the LoRA pricing; basically:
- If it's a LoRA of one of several popular base models listed on that page (e.g. Llama 3.1 70B Instruct, or Qwen 2.5 72B Instruct), we'll offer per-token pricing for it.
- For LoRAs of different base models, we still support running them! However, we'll charge them as on-demand models, at the cost of running the base model, since we still have to boot up a base model to run the LoRA. There's no extra charge for running the LoRA on top, though.
Higher rate limits
We've bumped everyone's rate limits even higher! The old rate limit was 4 requests per minute, on average over an eight-hour period (to allow for short spikes). The new rate limit is 60 requests per minute (aka, one request per second), also averaged over an eight-hour period to allow for short spikes. Have fun!
New sampler parameters in the UI
While the API has always supported these sampler parameters, the UI hasn't. In addition to launching support for system prompts last month, we've now added support for temperature, presence penalty, and frequency penalty sampler parameters.
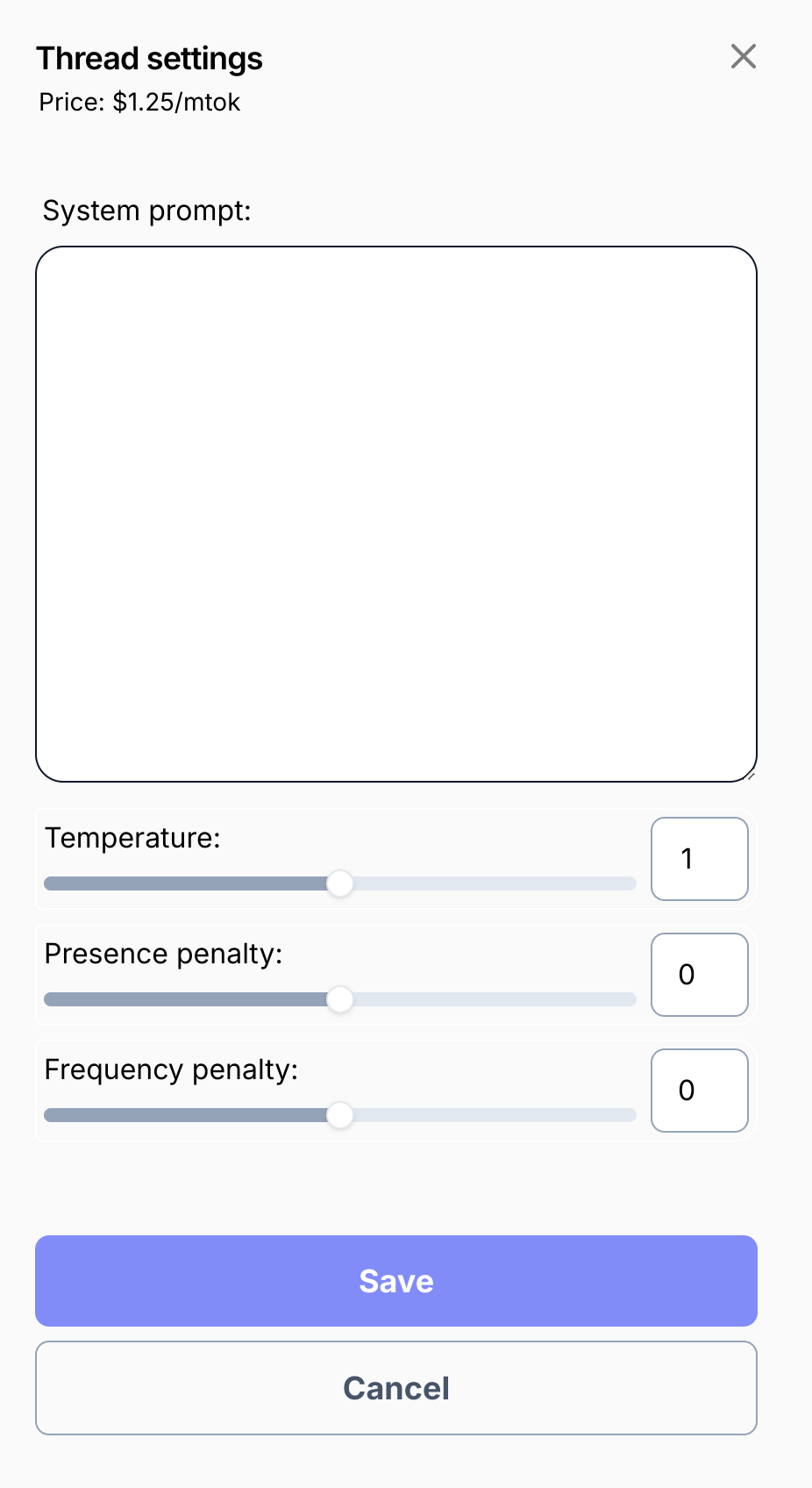
"Temperature" refers to the creativity of a model, vs its accuracy on the tasks it was trained on; a higher temperature makes the model more creative, but less accurate, whereas a lower temperature makes it more accurate but less creative.
Presence penalty and frequency penalties are ways to reduce the model's likelihood to repeat itself; presence penalty applies a flat penalty for any words that have been used already, and frequency penalty applies varying penalties to words depending on how many times they've been used: the more a word is used, the more it's penalized.
Check all of them out in the per-thread settings UI!
DeepSeek V3 and R1
As many of you have noticed... We now support DeepSeek V3 and R1, in addition to the distilled models we supported at launch. V3 and R1 are proxied to our partners at Together AI: your data stays in the U.S., and like all API use cases, we delete API prompts and completions within 14 days.
Various bugfixes, performance improvements, and UI tweaks
You've probably noticed the site becoming smoother and easier on the eyes over the last couple of months. That's no accident, and we'll keep working on it!
Future plans
If you made it here, thank you so much for your support and being a part of our journey!
We're hard at work on more improvements, including:
- Multi-modal input. We're text-only at the moment, but many of the models we serve can accept images, and we expect some will start working with audio this year as well. We want to support that!
- Infrastructure improvements for faster, cheaper on-demand models, in addition to the always-on LoRAs.
- Dark mode! We've had a lot of requests for this one and it's on our radar.
- Community Discord and better support options for active users.
- More backend and UI improvements. Maybe not the most exciting line item, but we're always bugfixing.
If you have any thoughts or feedback, please continue to reach out at [email protected]. We appreciate all the emails we've gotten so far!
— Matt & Billy